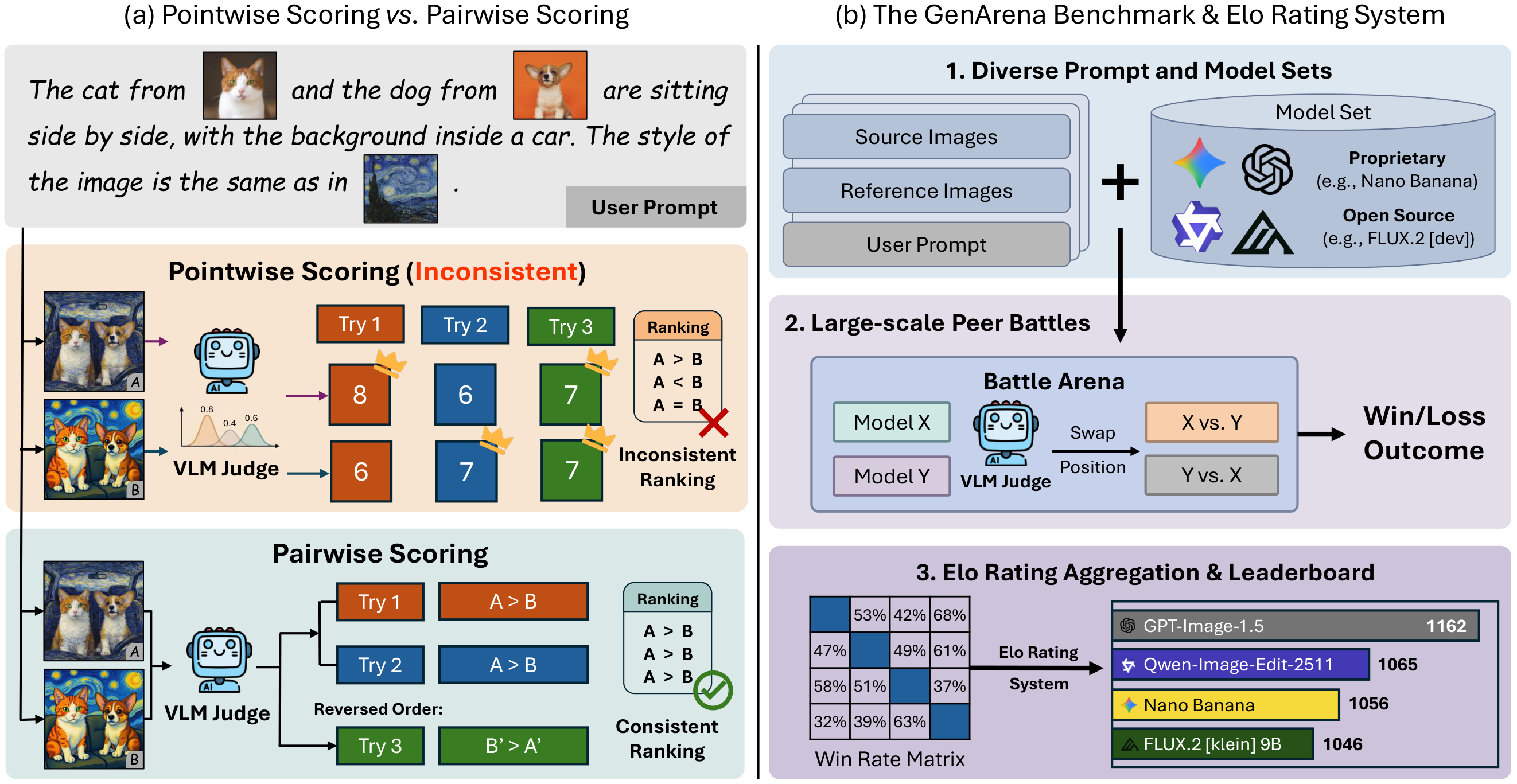
The rapid advancement of visual generation models has outpaced traditional evaluation approaches, necessitating the adoption of Vision-Language Models as surrogate judges. In this work, we systematically investigate the reliability of the prevailing absolute pointwise scoring standard, across a wide spectrum of visual generation tasks.
Our analysis reveals that this paradigm is limited due to stochastic inconsistency and poor alignment with human perception. To resolve these limitations, we introduce GenArena, a unified evaluation framework that leverages a pairwise comparison paradigm to ensure stable and human-aligned evaluation.
Crucially, our experiments uncover a transformative finding that simply adopting this pairwise protocol enables off-the-shelf open-source models to outperform top-tier proprietary models. Notably, our method boosts evaluation accuracy by over 20% and achieves a Spearman correlation of 0.86 with the authoritative LMArena leaderboard, drastically surpassing the 0.36 correlation of pointwise methods.
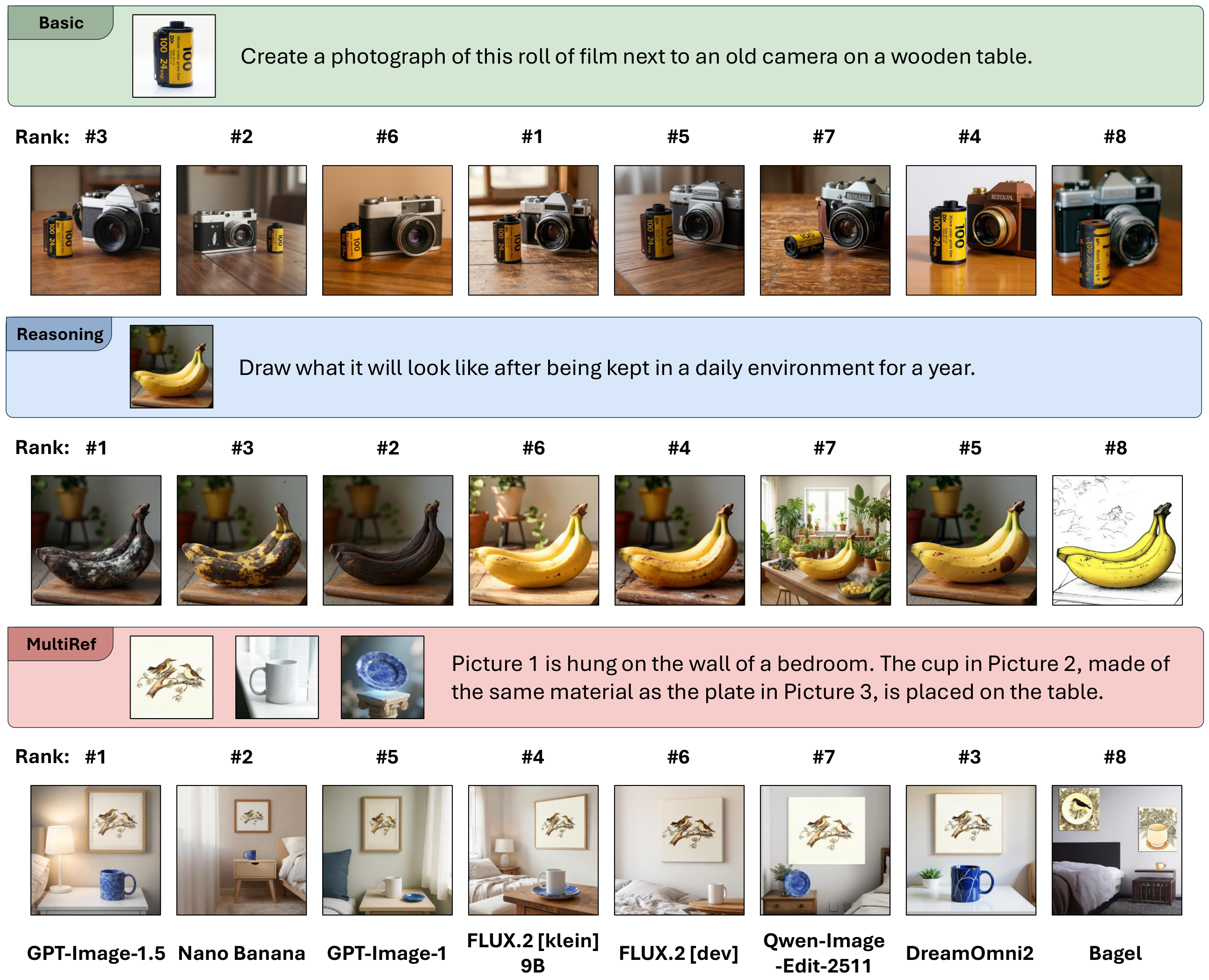
Based on GenArena, we benchmark state-of-the-art visual generation models across diverse tasks, providing the community with a rigorous and automated evaluation standard for visual generation.
 arXiv
Code
🤗
HuggingFace
Leaderboard
Diffgentor
Diffgentor is an efficient pipeline for batch image generation using various image editing models (e.g., for GenArena evaluation).
arXiv
Code
🤗
HuggingFace
Leaderboard
Diffgentor
Diffgentor is an efficient pipeline for batch image generation using various image editing models (e.g., for GenArena evaluation).